1.介绍
今天和大家介绍一个类似微信朋友圈的项目,适合记录生活。
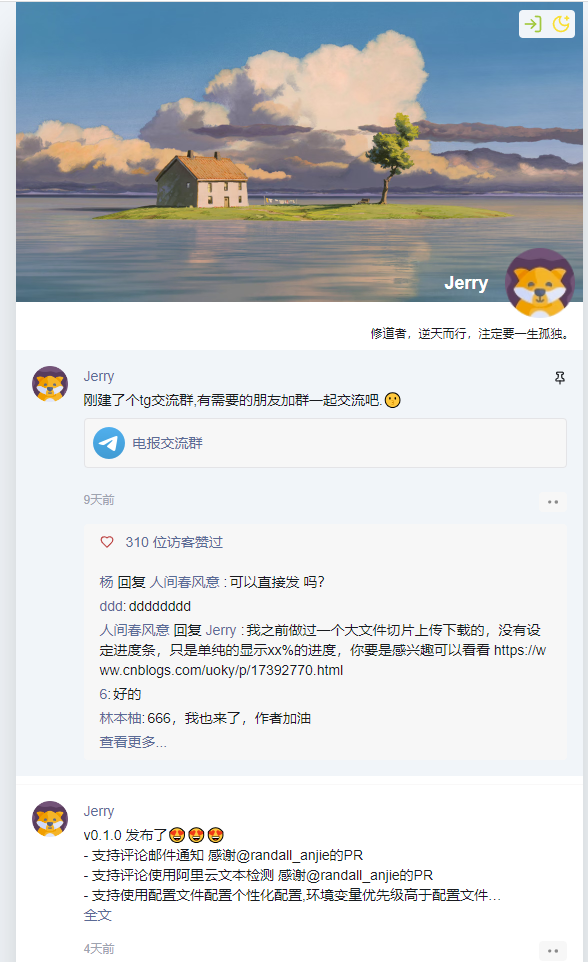
主要特色
- 支持匿名评论/点赞
- 支持引入网易云音乐,b站视频,插入链接等
- 支持自定义头图,个人头像,网站标题等
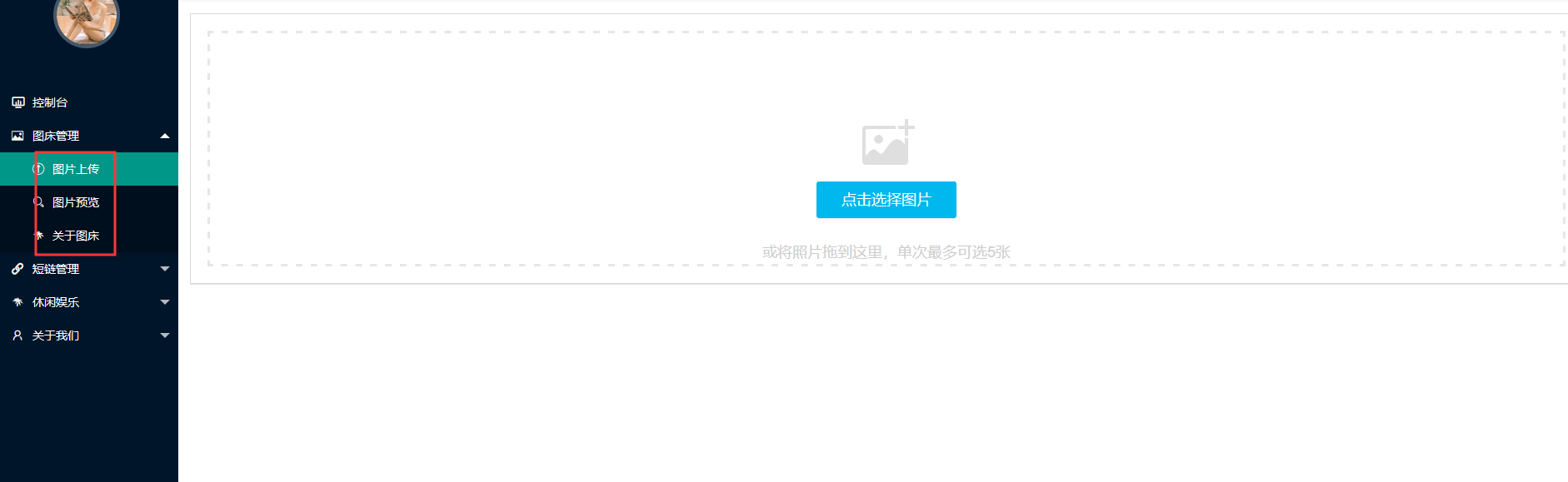
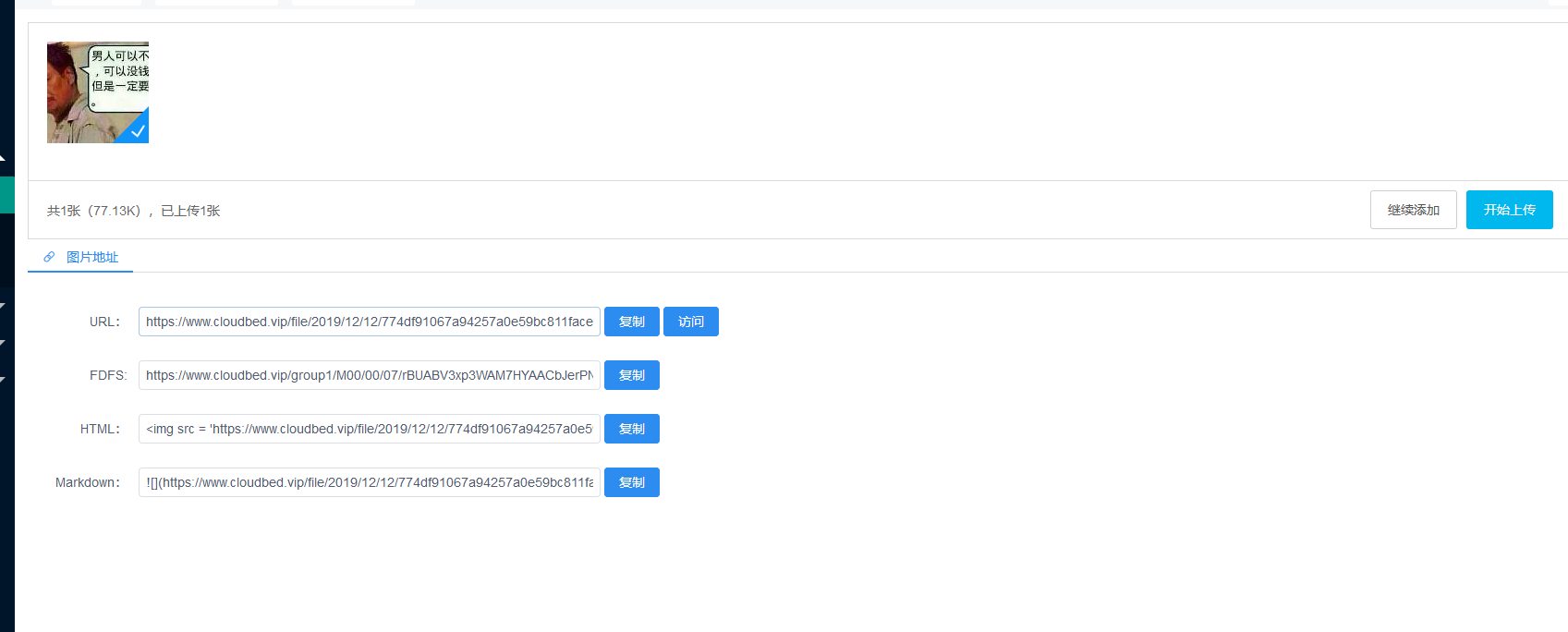
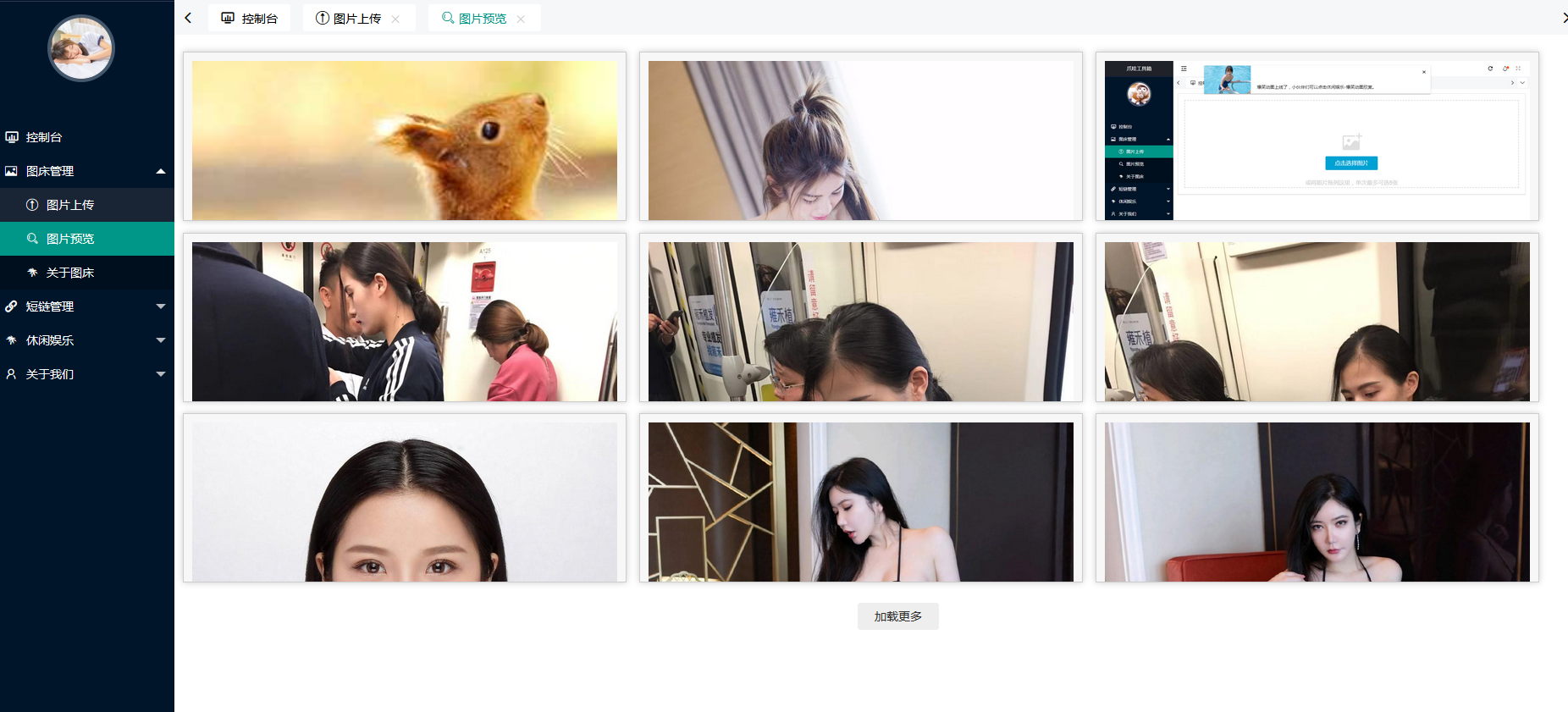
- 支持上传图片到S3兼容的云存储,支持本地存储
- 适配手机
- 支持暗黑模式
- 数据库采用sqlite,可随时备份
- 支持引入豆瓣读书/豆瓣电影,样式来源于这里
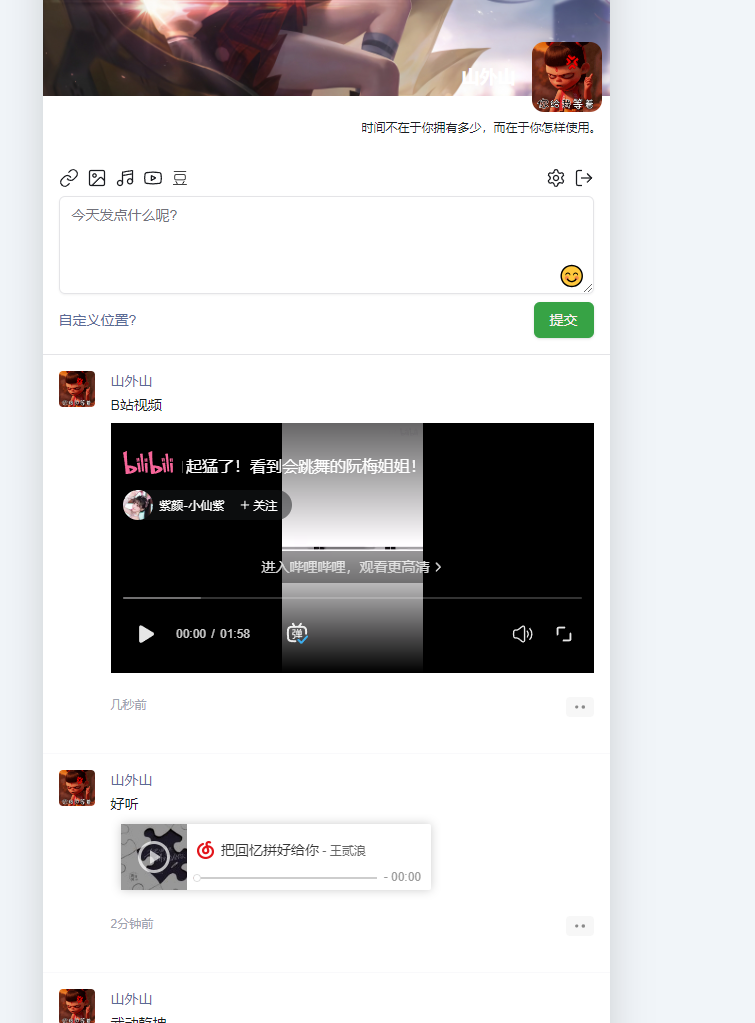
2.项目展示
作者的Demo:https://m.mblog.club/
自己的Demo:https://pyq.yunshare.top/
使用
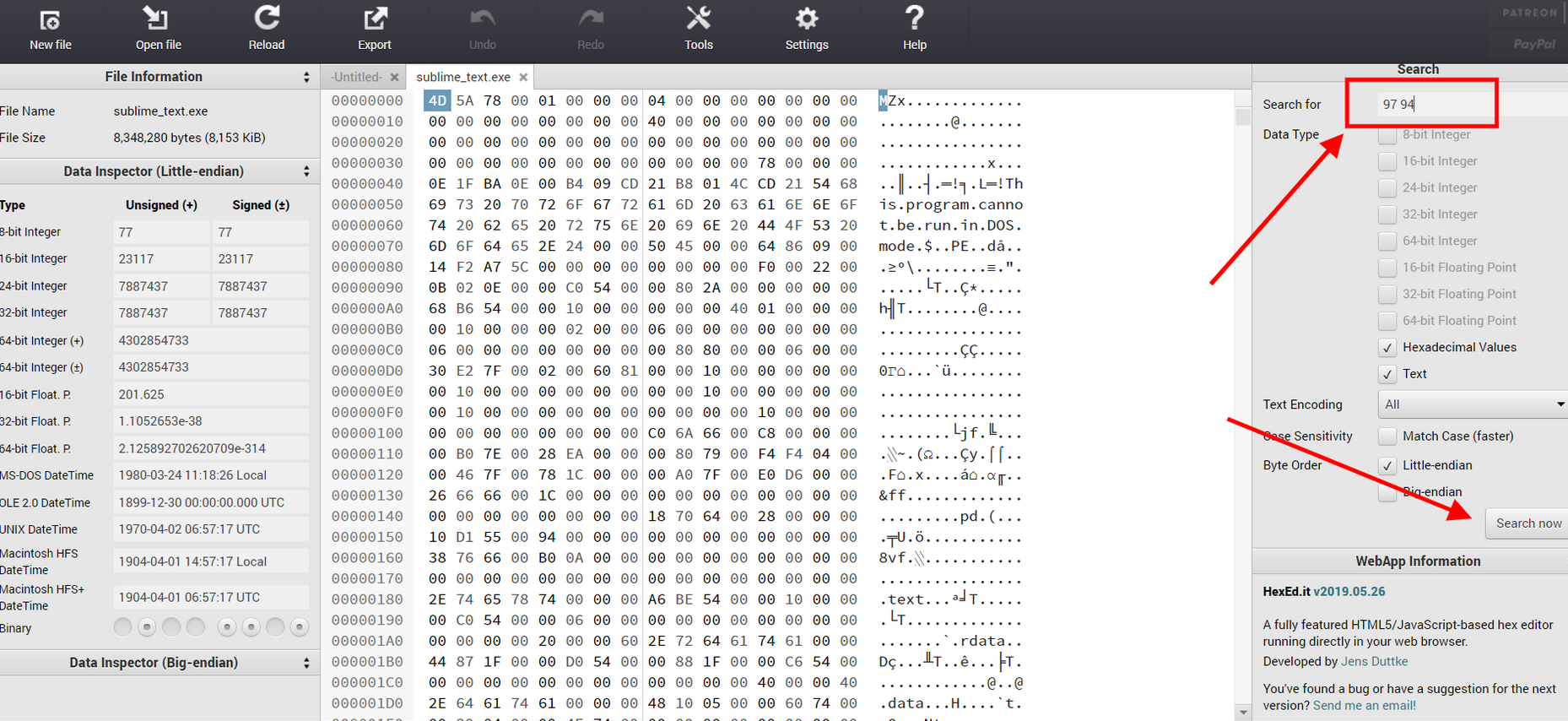
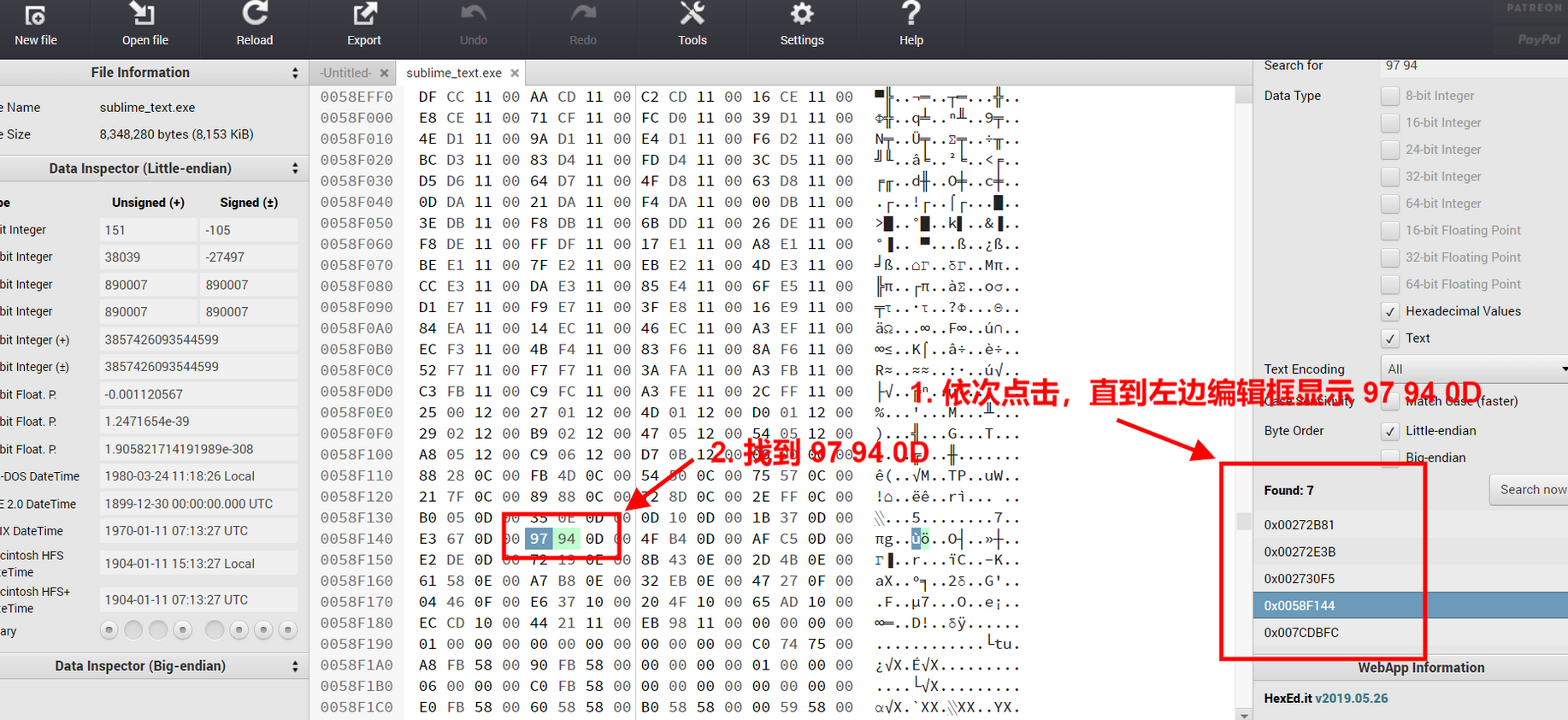
可以插入链接、上传图片、嵌入网易云音乐、插入B站视频、引入豆瓣读书和豆瓣电影
如何嵌入:https://jerry.mblog.club/simple-moments-import-music-and-video
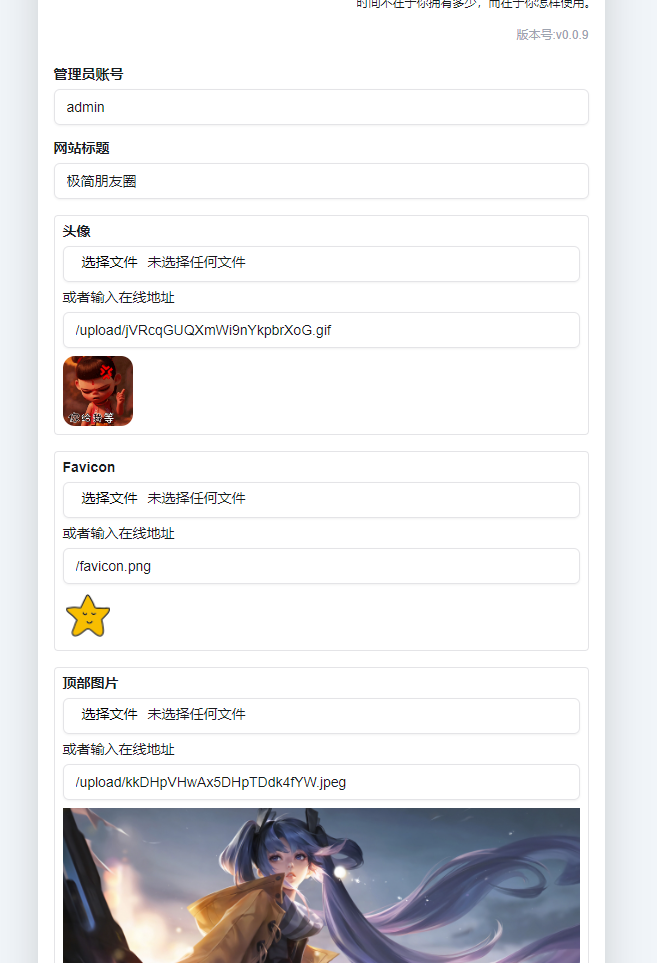
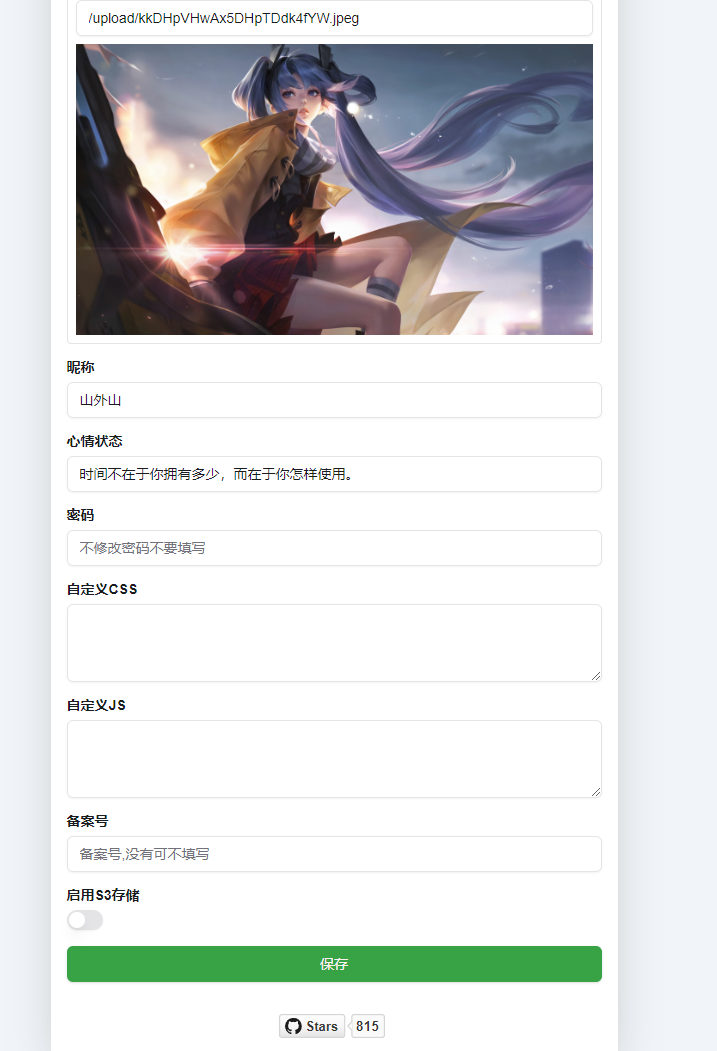
个人设置页面:
3.部署
Docker启动
Docker首次启动看这里
1 | basepath=$(cd `dirname $0`; pwd) |
Docker更新看这里
1 | basepath=$(cd `dirname $0`; pwd) |
Docker Compose启动
Docker Compose启动看这里
1 | version: '3' |
登录
默认用户名密码:admin/a123456,登录进去后后台可以自己修改密码
4.自定义其他配置
鉴于萝卜青菜各有所爱,每个人情况不一致,特此使用配置文件配置各项特性化需求,目前支持以下环境变量配置见.
同时也支持使用配置文件的方式,环境变量的优先级高于配置文件.
配置文件的使用方法:docker启动时把配置文件挂载进去,挂载目录为
1 | /app/data/config.properties |
你可以先复制这个文件,修改,然后挂载进docker内就可以了.
点我查看支持的个性化配置
| KEY | 默认值 | 描述 |
|---|---|---|
| NUXT_PUBLIC_PAGE_SIZE | 10 | 分页大小 |
| NUXT_PUBLIC_MOMENTS_COMMENT_ENABLE | true | 是否开启评论 |
| NUXT_PUBLIC_MOMENTS_SHOW_COMMENT | true | 是否显示评论 |
| NUXT_PUBLIC_MOMENTS_COMMENT_MAX_LENGTH | 120 | 评论最大字数 |
| NUXT_PUBLIC_MOMENTS_COMMENT_ORDER_BY | desc | 评论的显示顺序,desc:倒序,asc:顺序 |
| NUXT_PUBLIC_MOMENTS_TOOLBAR_ENABLE_DOUBAN | true | 是否显示引入豆瓣读书/视频按钮 |
| NUXT_PUBLIC_MOMENTS_TOOLBAR_ENABLE_MUSIC163 | true | 是否显示引入网易云音乐按钮 |
| NUXT_PUBLIC_MOMENTS_TOOLBAR_ENABLE_VIDEO | true | 是否显示引入youtube,b站,在线视频按钮 |
| NUXT_PUBLIC_MOMENTS_MAX_LINE | 4 | 单条发言最大行数,最大10行,超过折叠 |
| NUXT_PUBLIC_GOOGLE_RECAPTCHA_SITE_KEY | 无 | google recaptchaV3 HTML 代码中使用此网站密钥 |
| NUXT_GOOGLE_RECAPTCHA_SECRET_KEY | 无 | google recaptchaV3 网站和 reCAPTCHA 之间的通信密钥 |
| NUXT_PUBLIC_SITE_URL | 无 | 实例的访问地址 |
| NUXT_ENABLE_NOTIFY_BY_EMAIL | false | 是否启用评论通知 |
| NUXT_NOTIFY_MAIL | 无 | 管理员邮箱 |
| NUXT_MAIL_HOST | 无 | 邮件服务器地址 |
| NUXT_MAIL_PORT | 587 | 邮件服务器端口 |
| NUXT_MAIL_SECURE | false | 邮件服务器是否是安全连接 |
| NUXT_MAIL_NAME | 无 | 发件邮箱用户名 |
| NUXT_MAIL_PASSWORD | 无 | 发件邮箱密码 |
| NUXT_MAIL_FROM | 无 | 发件人邮箱 |
| NUXT_MAIL_FROM_NAME | 无 | 发件人名称 |
| NUXT_ALIYUN_TEXT_JUDGE_ENABLE | false | 是否启用阿里云文本审核(只针对评论) |
| NUXT_ALIYUN_ACCESS_KEY_ID | 无 | 阿里云AK |
| NUXT_ALIYUN_ACCESS_KEY_SECRET | 无 | 阿里云SK |
使用google recaptchaV3(可选)
自行去google recaptchaV3 admin console开通,每月100万次免费调用. 开通成功后复制网站密钥和通信密钥,填入上方的环境变量对应的key里面.
源码编译启动
首先设置环境变量:
1 | -- sqlite数据库位置 |
执行命令
1 | -- 安装依赖 |
编辑SQLITE数据库
1 | # 容器内部执行 |
执行上面的命令会在容器内部暴露一个5555端口,暴露到主机后可以通过 http://容器IP:5555 访问数据库,直接修改/删除/新增数据.
配置S3(可选)
由于使用了使用预签名 URL 上传对象方案来上传图片到S3,简单来说就是前端直接上传文件到S3,不经过服务端.
不支持这个预签名技术的S3无法上传,据我所知,号称兼容S3的云存储大部分都支持这个特性.比如腾讯云,七牛云,阿里云等.
另外,要求在S3上配置跨域,配置你当前的域名能够访问S3的资源,不配置的话,是无法使用的.
比如我这里使用的是缤纷云,配置如下:
重置密码
目前没有别的办法重置密码,只有修改数据库.见编辑SQLITE数据库.
或者任何能正常打开SQLITE数据库的工具都行,数据库见前面的环境变量部分.
打开bcrypt-generator或者其他类似的bcrypt在线加密的网站,加密你的密码.
复制加密后的密码,编辑数据库,更新User表pwd字段,更新完后记得关掉5555端口的映射,执行npx prisma studio命令停止5555端口.
4.相关地址
官方GitHub地址:https://github.com/kingwrcy/moments (目前815个star)
]]>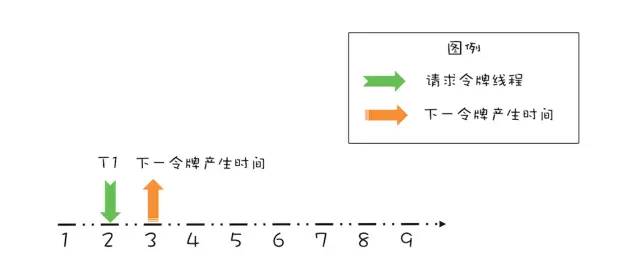 线程 T1 请求令牌示意图对于这个请求令牌的线程而言,很显然需要等待 1 秒,因为 1 秒以后(第 3 秒)它就能拿到令牌了。此时需要注意的是,下一个令牌发放的时间也要增加 1 秒,为什么呢?因为第 3 秒发放的令牌已经被线程 T1 预占了。处理之后如下图所示。
线程 T1 请求令牌示意图对于这个请求令牌的线程而言,很显然需要等待 1 秒,因为 1 秒以后(第 3 秒)它就能拿到令牌了。此时需要注意的是,下一个令牌发放的时间也要增加 1 秒,为什么呢?因为第 3 秒发放的令牌已经被线程 T1 预占了。处理之后如下图所示。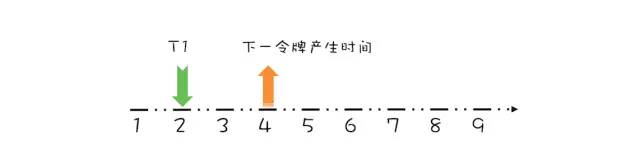 线程 T1 请求结束示意图假设 T1 在预占了第 3 秒的令牌之后,马上又有一个线程 T2 请求令牌,如下图所示。
线程 T1 请求结束示意图假设 T1 在预占了第 3 秒的令牌之后,马上又有一个线程 T2 请求令牌,如下图所示。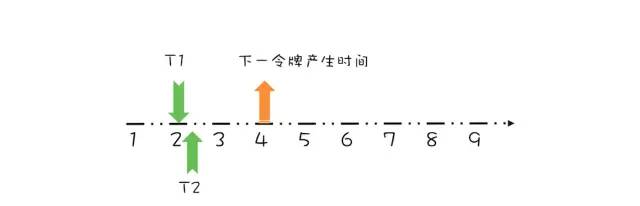 线程 T2 请求结束示意图上面线程 T1、T2 都是在下一令牌产生时间之前请求令牌,如果线程在下一令牌产生时间之后请求令牌会如何呢?假设在线程 T1 请求令牌之后的 5 秒,也就是第 7 秒,线程 T3 请求令牌,如下图所示。
线程 T2 请求结束示意图上面线程 T1、T2 都是在下一令牌产生时间之前请求令牌,如果线程在下一令牌产生时间之后请求令牌会如何呢?假设在线程 T1 请求令牌之后的 5 秒,也就是第 7 秒,线程 T3 请求令牌,如下图所示。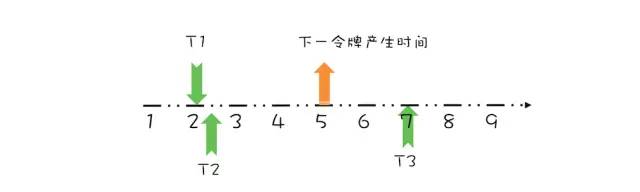 线程 T3 请求令牌示意图由于在第 5 秒已经产生了一个令牌,所以此时线程 T3 可以直接拿到令牌,而无需等待。在第 7 秒,实际上限流器能够产生 3 个令牌,第 5、6、7 秒各产生一个令牌。由于我们假设令牌桶的容量是 1,所以第 6、7 秒产生的令牌就丢弃了,其实等价地你也可以认为是保留的第 7 秒的令牌,丢弃的第 5、6 秒的令牌,也就是说第 7 秒的令牌被线程 T3 占有了,于是下一令牌的的产生时间应该是第 8 秒,如下图所示。
线程 T3 请求令牌示意图由于在第 5 秒已经产生了一个令牌,所以此时线程 T3 可以直接拿到令牌,而无需等待。在第 7 秒,实际上限流器能够产生 3 个令牌,第 5、6、7 秒各产生一个令牌。由于我们假设令牌桶的容量是 1,所以第 6、7 秒产生的令牌就丢弃了,其实等价地你也可以认为是保留的第 7 秒的令牌,丢弃的第 5、6 秒的令牌,也就是说第 7 秒的令牌被线程 T3 占有了,于是下一令牌的的产生时间应该是第 8 秒,如下图所示。 线程 T3 请求结束示意图通过上面简要地分析,你会发现,我们只需要记录一个下一令牌产生的时间,并动态更新它,就能够轻松完成限流功能 。我们可以将上面的这个算法代码化,示例代码如下所示,依然假设令牌桶的容量是 1。关键是
线程 T3 请求结束示意图通过上面简要地分析,你会发现,我们只需要记录一个下一令牌产生的时间,并动态更新它,就能够轻松完成限流功能 。我们可以将上面的这个算法代码化,示例代码如下所示,依然假设令牌桶的容量是 1。关键是 

































{kind=link}
{kind=link}